在当前的生成式人工智能应用中,不同的任务需求决定了选择不同的平台和模型至关重要。根据网络条件、费用以及使用场景的不同,用户在访问和使用大语言模型时,需要根据任务的复杂性、推理需求以及具体的操作类型(如编程、文本生成等)做出相应的调整。
0. 一般原则
- 使用 大模型 替代你的脑力活动中的重复性劳力,而不是创造性思考。
- 使用 大模型 为你提供头脑风暴参考,但要确保你的判断力是可靠且理性的。
- 时常想想,大模型弱化了你的哪种能力,以及你是否容许它弱化你的这种能力。
- 代码是大模型和你的任务之间的重要桥接,能够很大程度上规避模型幻觉问题。与其让大模型为你提供处理结果,不如让它生成可复用的代码。
- 模型回答结果不理想时思考:① 可否换用在这项任务上更强的模型?② 你的提示词是否逻辑清晰、明确,包含必要的解释和案例?大多数情况下,由于问题 ② 的普遍,使得问题 ① 的上限远未被触及。
- 好的提示词长什么样的?可以参考这个 Github 仓库,它收集了 GPTs 泄露出的大量系统提示词。
- 有时我们需要结果也需要过程,例如阅读文献的实际收益在阅读前是未知的,使用大模型对 PDF 提问往往舍弃了阅读文献带给你我的真正启发。
1. 在线平台选择
- 免费:
- 直接访问 OpenAi 官网使用免费 4o-mini 模型(需要有网络条件)
- 访问 POE 使用免费模型(需要有网络条件)
- 付费(订阅制):
- 如需 Openai 的高级模型(4o/o1-preview)需要付月费(安卓手机绑定外币信用卡支付)
- 或使用 Claude 中的高级模型(Sonnet 3.5)需要付月费
- 付费(按 Token 计费):
- NYai 包含很多高级模型,按量收费(最贵的模型一次问答 0.2元 左右),有免费额度。
2. 在线模型选择
- 复杂推理:GPT-o1 preview
- 轻推理重文字输出:GPT-4o
- 代码编写与 Debug: Claude 3.5 sonnet = Cursor > GPT-o1 preview > GPT-4o (不要使用其他模型编程,比如 Kimi )
- 搜索结果归纳: 跃问 > Kimi >> 智谱清言 (不基于搜索结果的任何「知识性/逻辑性」问题都不建议问 Kimi,使用 智谱清言 的唯一场景是「这模型真的有说的那么差吗?我倒要看看。」)
3. 离线(本地)大语言模型选择
- 中文模型:Qwen2.5 > GLM4
- 英文模型:Llama3.1
- 多种模型及参数量比较:本地语言模型个人推荐 (2024-07-09)
- 离线大模型平台:Ollama (能被 Ollama 支持的模型,就不要自己搭建环境)
4. 离线(本地)模型硬件选择
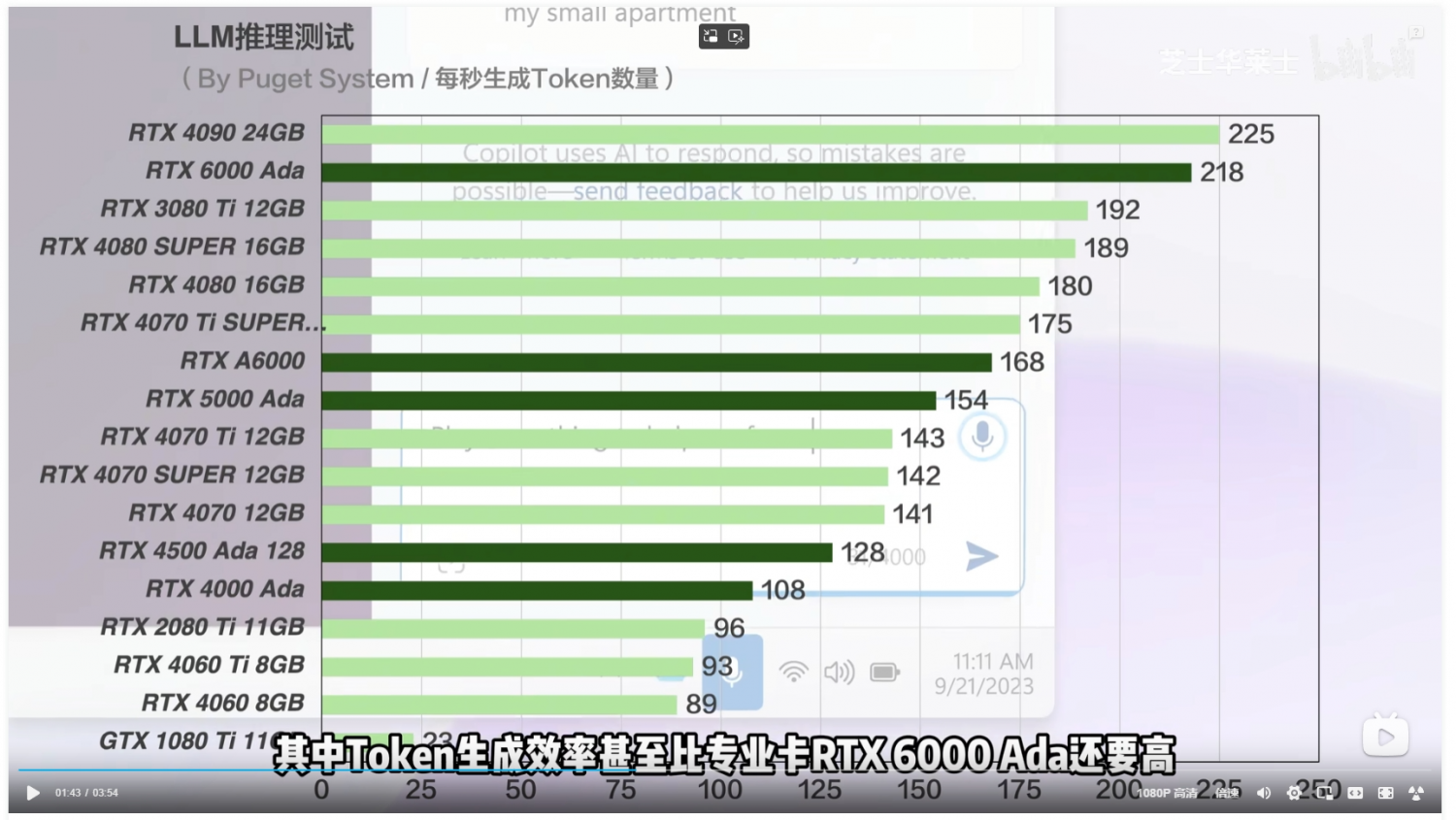
5. 理论及原理学习
6. 提示词工程参考
Z. 总结
- 没有网络条件或需要少量且高质量的问答,使用 NYai 。
- 高质量问答指的是「需要复杂逻辑推理/生成准确代码」,前者使用 GPT-o1 preview 后者使用 Claude 3.5 sonnet。
- 代码输出仅推荐 Claude 3.5 sonnet,其次 Cursor、GPT-o1 preview,不要使用任何其他模型输出代码,它们往往给你带来的帮助和苦恼一样多。
- Kimi 大模型能力很弱,它强在基于搜索结果的答案整合,如果你确信你需要答案不在搜索结果中,那就别用 Kimi 。
- 慎重使用:xlchatbox.top,已被举报封禁。

